
Introducing VLM Run Blog
Large Language Models have transformed how we work with text, but visual content—images, videos, and visually-rich documents—remains largely untapped. Over 80% of unstructured data is locked away due to the lack of effective developer tools for extracting and understanding it. Developers want a single API for vision that "just works," but visual use-cases are complex, often requiring deep expertise and months of R&D to bring into production.
At VLM Run, we're building the Unified Gateway for Visual AI to help enterprises unlock this "dark visual data." Our platform is powered by small, specialized Vision Language Models (VLMs) tailored to industry-specific needs, offering a unique approach that larger, general-purpose models overlook. We're betting that these specialized VLMs will drive much of this transformation in the coming years, becoming the foundation for visual data processing in various sectors. From retail inventory management and web content moderation to RPA, back-office document processing, healthcare forms, and insurance claims, enterprises will rely on VLMs fine-tuned for their verticals.
Meet VLM-1: Your ETL-Ready VLM
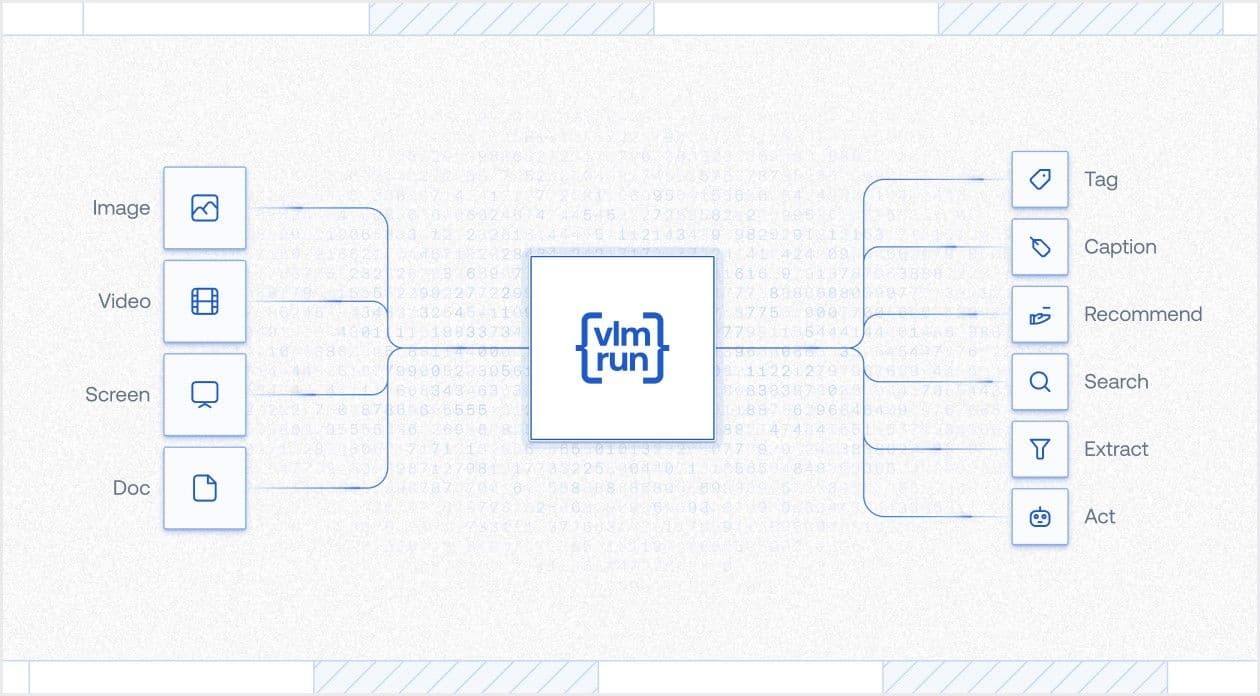
Our flagship Vision-Language Model vlm-1 aims to radically simplify visual content understanding from images, videos and documents. Our unified API allows developers to harness the power of VLMs for a wide range of tasks including OCR, tagging, image-captioning, visual recommendation and search all under one roof. But unlike other chat-based models, our models are specifically designed for visual ETL. Our APIs enable developers to easily and accurately extract JSON with strict-typing from any visual content such as images, videos screenshots, or rich visual documents.

Stay tuned
We're gearing up for an exciting series of launches that will revolutionize how developers work with visual AI. In the coming weeks, we'll be unveiling new features that make enterprise-grade computer vision more accessible than ever—think fast inference with structured outputs, seamless API integration to industry-verticals, and cost-effective inference scaling of VLMs to large volumes of images and videos (including streaming-support) that works out of the box. Stay tuned to our blog as we roll out announcements that will reshape the visual AI landscape. Want to be first in line? Join our waiting list to get early access and start building the future of visual AI with VLM Run.


